
|
О сайте Регистрация Обратная связь Реклама на сайте Публикации на сайте Карикатуры |
|
|
|
|
| Серверы : Теория |
20.09.2003. Управление производительностью вычислительных систем на примере RISC-серверов Sun
Производительность — главный показатель работоспособности системы. Не обладая необходимой производительностью, она не способна выполнять возложенные на нее задачи. И примеров тому можно привести массу: невозможность своевременно отреагировать на изменение конъюнктуры рынка из-за задержки аналитической обработки данных (OLAP), отказ в обслуживании клиента из-за перегрузки системы (процессинг), срыв сроков поставок (ERP) или подачи отчетов в фискальные органы и т. д. В результате сроки выполнения бизнес-задач могут оказаться сорванными, что в конечном итоге приведет к финансовым потерям компании. На снижение производительности влияют многие факторы: от выхода из строя компонентов вычислительных средств до ошибки в проектировании. Однако, даже если система хорошо спроектирована, ее производительность может перестать удовлетворять требованиям бизнеса в случае их изменения: например, когда происходит незапланированный рост числа пользователей или объемов данных, появляются новые задачи и т. п. Чтобы падение производительности не стало неприятным сюрпризом, ее уровень надо постоянно отслеживать и корректировать. Сделать это помогает методика управления уровнем сервиса (Service Level Management, SLM), следование которой позволяет держать в заданных рамках все показатели — не только производительности, но и готовности информационных сервисов ИС. 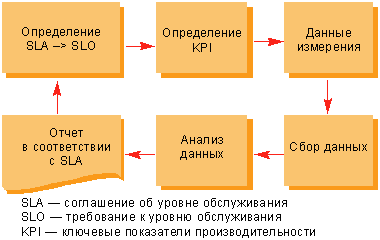
Рисунок 1. Процесс управления уровнем обслуживания. В соответствии с данной методикой (см. Рисунок 1), необходимо определить, какие показатели производительности должна иметь вычислительная система, как их измерять и каким образом полученные данные отражают реальную картину. Для решения проблемы снижения производительности необходимо предпринять адекватные меры по ее устранению. Приобретение более мощного оборудования не является панацеей от всех бед. Во многих случаях помогает оптимизация системы, но рецептов на все случаи жизни не существует. Вопросы выбора показателей производительности системы, их измерения и анализа полученных данных рассматриваются далее на примере платформы SPARC/Solaris. В заключение статьи приводится ряд рекомендаций по оптимизации ОС Solaris для повышения производительности при работе с СУБД Oracle. Каких целей хочется достичьС момента появления вычислительной техники пользователи хотят, чтобы компьютеры работали быстрее. Но всегда ли нужно идти у них на поводу? Если сервер способен обработать 10 тыс. транзакций в секунду, много это или мало? На первый взгляд для банка, у которого всего 10 тыс. клиентов, такая производительность более чем достаточна, а для оператора мобильной связи с тем же числом абонентов вроде бы маловата. Однако если в банке одновременно с интерактивным обслуживанием клиентов сотня экспертов выполняет сложные аналитические задачи с использованием тех же финансовых транзакций, то сервер автоматизированной банковской системы (АБС) может не успеть выполнить запрос на обслуживание важного клиента, что грозит потерей денег — клиент предъявит иск или просто откажется от услуг банка. Напротив, если сервер биллинговой системы оператора мобильной связи не успеет обработать детальную запись о звонке абонента (Call Detailed Record, CDR), то он имеет возможность сделать это в следующую итерацию, поскольку коммутаторы сети мобильной связи обычно хранят CDR некоторое время. Итак, 10 тыс. транзакций в секунду — это много или мало? Ответ зависит от того, выполнение каких задач возложено на сервер и какие требования при этом предъявляются. Например, в случае АБС банка сервер должен выполнить запрос клиента на осуществление финансовой транзакции не более чем за 30 с, а для биллинговой системы оператора мобильной связи требование может выглядеть иначе — сервер должен суметь обработать за 1 мин не менее 5000 CDR. Если требования изначально не определены, то измерение производительности системы становится бессмысленным занятием. Требования обычно фиксируются в соглашении об уровне обслуживания (Service Level Agreement, SLA). SLA — это полноценный контракт между провайдером услуг и потребителем, который в наших примерах может быть заключен между службой ИТ банка и руководством банка, отделом эксплуатации биллинговой системы и службой биллинга. Он необходим для оценки уровня услуг ИТ и обеспечения управления этим уровнем. Как правило, SLA оговаривает такие параметры, как коэффициент готовности услуги (доступность), нормативы устранения сбоев, а также показатели производительности (Key Performance Indicator, KPI). Зафиксированные в SLA требования (Service Level Objective, SLO) говорят о том, какую производительность системы необходимо поддерживать, а KPI позволяют установить, что производительность системы находится на должном уровне. (SLO для АБС банка и биллинговой системы уже были сформулированы выше.) Кроме того, в SLO указывают, как учитывается время обработки: в частности, для финансовых транзакций — это может быть интервал времени между отправкой запроса на выполнение транзакции и получением визуального подтверждения его выполнения. Для АБС банка KPI могут быть сформулированы как доля транзакций, время обработки которых превышает определенный порог, например 28 с. Если количество подобных финансовых транзакций вышло за заданный порог, например 5 %, то можно говорить о падении производительности системы и следует принять меры к ликвидации данной ситуации. Для биллинговой системы KPI формулируются проще — как минимальное число CDR, обрабатываемых за 1 мин. Что измерять?К сожалению, использование KPI позволяет только фиксировать факт снижения производительности, но не раскрывает причины происходящего. На практике производительность грамотно спроектированной системы не должна падать при отсутствии каких-либо существенных изменений во внешних условиях функционирования, отказов оборудования или неумелого вмешательства администраторов в ее работу. Как правило, истемы проектируются с запасом производительности и масштабируемости на случай увеличения нагрузок вследствие прироста объемов обрабатываемых данных и числа пользователей. Незапланированное резкое увеличение числа пользователей (в частности, в результате создания нового подразделения) или появление новых задач является существенным изменением внешних условий функционирования. Поэтому, если система стала медленнее работать, прежде всего надо выяснить, какие случились перемены. Как уже было отмечено, обычно KPI не позволяют определить, что могло повлиять на нормальную работу системы. Кроме того, измерение параметров KPI не всегда возможно или удобно осуществлять в том виде, в каком они заданы в SLA. Обычно значение KPI зависит от производительности множества компонентов системы: сети, прикладного программного обеспечения и сервера. У каждого из данных компонентов существуют индикаторы производительности. Для сервера такими индикаторами служат загруженность процессорных мощностей, используемый объем оперативной памяти, число выполняемых процессов и др. KPI являются интегральным показателем, и зачастую формулу их расчета невозможно вывести из индикаторов производительности отдельных компонентов системы, особенно если последняя состоит из большого числа серверов, сетевых коммутаторов, дисковых массивов, коммутаторов Fibre Channel и т. д. В таком случае измеряют показатели производительности компонентов работающей системы, когда она обеспечивает требуемую производительность. Полученные значения используют как базовые (baseline) для сравнения с текущими показателями производительности компонентов при дальнейших контрольных замерах. Если конфигурация системы изменяется или претерпевает модернизацию, то определение базовых значений производится вновь. Вместе с тем, открытым остается вопрос: какие показатели производительности отнести к базовым? Все измеряемые показатели попадают в одну из четырех категорий: производительность, время отклика / обслуживания, длина очереди и утилизация.
Приведенные показатели связаны следующими формулами: service time = utilization ⁄ throughput queue length = throughput × response time Так какие же параметры системы необходимо измерять? Ответ вполне очевиден: те, которые в дальнейшем помогут выявить приводящие к потере производительности «узкие» места. Как уже говорилось ранее, в любой системе имеются три компонента, где могут возникать «узкие» места, — это сеть, прикладное ПО и сервер. Для каждого из них существует свой набор показателей, на основании которых оказывается возможным выявить проблемы с производительностью. Еще раз подчеркнем, что все эти показатели попадают в одну из четырех упомянутых ранее категорий: производительность, время отклика / обслуживания, длина очереди и утилизация. Процесс анализа показателей производительности рассмотрим на примере платформы SPARC/Solaris. В ядре операционной системы в специальных счетчиках накапливается статистика о работе компонентов системы. Для отображения статистики функционирования различных компонентов сервера и операционной системы платформы SPARC/Solaris используются следующие команды:
В других системах UNIX, берущих свое начало от AT&T System V, для отображения статистики служат аналогичные команды. Так, в HP-UX 11i v1 — это vmstat, mpstat, iostat, netstat, причем они отображают практически ту же информацию, что и команды ОС Solaris. Однако методика анализа их результатов для ОС Solaris и для HP-UX различна в связи с отличиями во внутренних структурах указанных ОС. Поиск «узких» мест, влияющих на производительность сервера, рекомендуется начинать с анализа статистики использования памяти. Зачастую недостаток памяти ошибочно диагностируется как медленный доступ к диску или нехватка процессорной мощности. Для получения статистики применяйте команду vmstat (см. Листинг 1). В первую очередь следует обратить внимание на значения в колонке sr (scan rate). Они показывают число страниц памяти, которые ядро операционной системы просматривало в попытке найти свободную страницу. Когда указанная величина в колонке sr возрастает, одновременно увеличивается значение в колонке po (page-outs), показывающее число страниц физической памяти, выгружаемых на диск в область swap. Если такая ситуация наблюдается постоянно, то серверу не хватает памяти для выполнения задач, и из-за этого падает производительность. 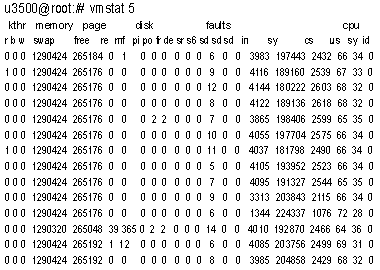
Листинг 1. При поиске «узких» мест нужно обратить внимание и на статистику загрузки процессоров. Детальную информацию можно получить с помощью команды mpstat (см. Листинг 2). Важными для анализа являются следующие показатели:
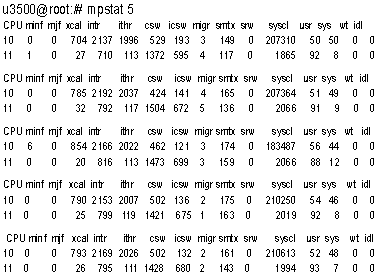
Листинг 2. Если значения в колонке idl постоянно близки к нулю, значит, серверу не хватает процессорной мощности для выполнения задач. Обратное не всегда верно. Время, которое процессор тратит на обработку прерываний сетевого ввода-вывода (и ряда других), учитывается как idl, поскольку приоритет таких прерываний выше, чем приоритет прерываний таймера сбора статистики. В результате якобы бездействующий сервер (высокие значения idl) в действительности может быть занят обработкой сетевого трафика. Помимо описанной возможен и ряд других подобных ситуаций, когда необходимо учитывать значения приведенных показателей в комплексе, что отражено в Таблице 1. На Листинге 2 видно, что сложная вычислительная задача (idl = 0) не мешает серверу справляться с нагрузкой — все остальные параметры в норме. 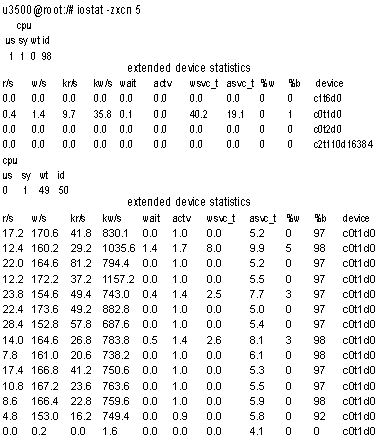
Листинг 3. Аналогично командам vmstat и mpstat, внимания заслуживает только часть показателей, выдаваемых командой iostat (см. Листинг 3). К ним относятся:
Если последние три показателя близки к нулю, то это означает, что серверные диски достаточно быстрые, а ввод-вывод оптимально распределен между контроллерами и не создает «узких» мест, то есть «всё в норме». На практике для диска, находящегося под нагрузкой, значения показателя asvc_t будут не нулевые, поскольку любому диску требуется некоторое время на исполнение запросов ввода-вывода. 
Листинг 4. К сожалению, встроенная в Solaris команда netstat выдает очень ограниченный набор информации (см. Листинг 4), на основании которой можно было бы сделать адекватные выводы о проблемах с производительностью сети. Нужно обратить внимание лишь на то, чтобы число ошибок (errs) и коллизий (colls) было близко или равнялось нулю. Применение рассмотренных выше команд удобно при анализе функционирования одного-единственного сервера. Если же необходимо контролировать работу нескольких серверов и своевременно выявлять неполадки, то лучше воспользоваться развитыми средствами, в частности коммерческими пакетами Sun Management Center, HP OpenView или BMC PATROL. Перечисленные продукты имеют развитый механизм задания правил, на основе которых они сообщают администратору о проблеме с производительностью (и не только) на контролируемых серверах. Детальное рассмотрение указанных продуктов выходит за рамки этой статьи. Практический опыт создания и эксплуатации систем показывает, что наибольший выигрыш можно получить путем оптимизации не настроек сервера, а приложения. К сожалению, в силу ряда причин это не всегда возможно (например, из-за отсутствия исходного кода), поэтому еще одной точкой приложения усилий является оптимизация настроек такого программного обеспечения, как СУБД Oracle. Но прежде, чем заниматься настройками, необходимо проанализировать статистику работы СУБД. С этой целью в Oracle используются специальные системные виды (View), названия которых начинаются с v$. Эти объекты представляют внутренние структуры Oracle, где накапливается статистика. Процесс накопления статистики должен быть включен, например, с помощью команды:
Для облегчения получения статистики в поставку Oracle входят два сценария: utlbstat.sql и utlestat.sql. Запуск utlbstat.sql инициализирует процесс сбора статистики и создания отчета, по окончании определенного промежутка времени необходимо запустить сценарий utlestat.sql, чтобы сгенерировать отчет о работе СУБД за этот период. Результат будет помещен в файл report.txt. Детальное рассмотрение всех параметров СУБД Oracle, которые необходимо проанализировать для выявления «узких» мест, опять же выходит за рамки данной статьи. (Более подробную информацию можно найти по указанным в «Ресурсах Internet» ссылках.) Что предпринять?Как уже отмечалось вначале, рецептов по оптимизации системы на все случаи жизни не существует. К универсальным советам можно отнести только следующие очевидные рекомендации:
Относительно оптимизации производительности СУБД Oracle под управлением ОС Solaris можно дать следующие общие рекомендации:
Ресурсы InternetБольшую часть необходимой литературы для детального изучения вопросов управления производительностью на платформе SPARC/Solaris можно найти на общедоступном сайте www.sun.com/blueprints:
Алексей Лобанов —
ведущий эксперт Департамента системных решений компании IBS. Статью "20.09.2003. Управление производительностью вычислительных систем на примере RISC-серверов Sun" |
||||||||||||||||
|
|
| Copyright by MorePC - обзоры, характеристики, рейтинги мониторов, принтеров, ноутбуков, сканеров и др. | info@morepc.ru |